Qwen2.5-Max: โมเดลขนาดใหญ่แบบ MoE ที่พัฒนาโดย Alibaba Cloud เปิดให้ใช้งานผ่าน API แล้ว
Alibaba Cloud เปิดตัว Qwen2.5-Max โมเดลขนาดใหญ่แบบ Mixture-of-Experts (MoE) ที่ได้รับการฝึกด้วยข้อมูลมากกว่า 20 ล้านล้านโทเคน พร้อมปรับแต่งด้วยเทคนิค Supervised Fine-Tuning (SFT) และ Reinforcement Learning from Human Feedback (RLHF) ล่าสุด โดยโมเดลนี้มีให้ใช้งานแล้วผ่าน Qwen Chat และ API บน Alibaba Cloud
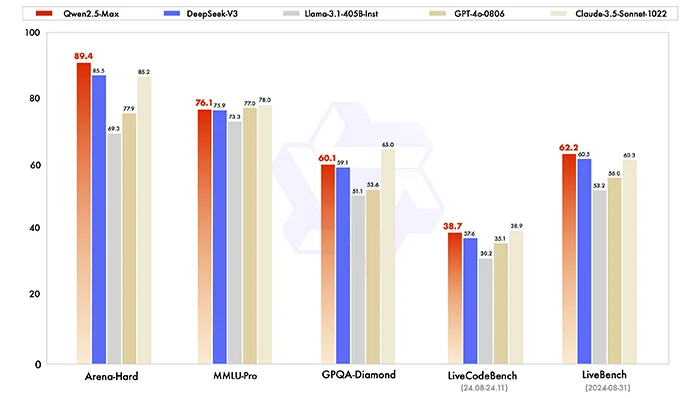
Qwen2.5-Max ได้รับการทดสอบและเปรียบเทียบกับโมเดลระดับแนวหน้าหลายตัว เช่น DeepSeek V3, GPT-4o และ Claude-3.5-Sonnet ในหลายชุดการทดสอบ เช่น MMLU-Pro สำหรับการประเมินความรู้ระดับมหาวิทยาลัย, LiveCodeBench สำหรับความสามารถด้านการเขียนโค้ด, LiveBench สำหรับการทดสอบความสามารถทั่วไป และ Arena-Hard ซึ่งวัดความสามารถตามหลักเกณฑ์ที่ใกล้เคียงกับการประเมินของมนุษย์
ผลลัพธ์แสดงให้เห็นว่า Qwen2.5-Max ทำคะแนนได้เหนือกว่า DeepSeek V3 ในหลายหมวดหมู่ รวมถึง Arena-Hard, LiveBench, LiveCodeBench และ GPQA-Diamond และยังคงทำคะแนนได้ใกล้เคียงกับโมเดลระดับสูงในหมวดอื่น ๆ
สำหรับการเปรียบเทียบโมเดลพื้นฐาน (Base Model) ทางทีมพัฒนาได้นำ Qwen2.5-Max มาเทียบกับ DeepSeek V3, Llama-3.1-405B และ Qwen2.5-72B ซึ่งเป็นโมเดลขนาดใหญ่ที่เปิดให้ใช้งานฟรี โดยผลการทดสอบแสดงให้เห็นว่า Qwen2.5-Max มีความสามารถที่โดดเด่นในหลายด้าน และมีศักยภาพที่จะพัฒนาได้ไกลยิ่งขึ้นด้วยเทคนิคการฝึกหลังการเทรน (Post-training)
การใช้งาน Qwen2.5-Max
โมเดล Qwen2.5-Max สามารถใช้งานได้แล้วผ่าน Qwen Chat โดยผู้ใช้สามารถสนทนา ทดสอบการทำงานของโมเดล หรือใช้งานความสามารถพิเศษต่าง ๆ ได้โดยตรง
สำหรับนักพัฒนา Qwen2.5-Max เปิดให้เรียกใช้งานผ่าน API ของ Alibaba Cloud โดยใช้โมเดลภายใต้ชื่อ “qwen-max-2025-01-25” โดยสามารถสมัครบัญชี Alibaba Cloud และเปิดใช้บริการ Model Studio เพื่อสร้าง API Key สำหรับเรียกใช้งานโมเดลนี้ได้
Qwen2.5-Max รองรับการใช้งานผ่าน API ในรูปแบบ OpenAI-compatible API ซึ่งหมายความว่าผู้ใช้สามารถเรียกใช้งานโมเดลผ่านโค้ดที่คุ้นเคย เช่น Python ได้ตามปกติ
ทีมพัฒนาระบุว่า การขยายขนาดของโมเดลและปริมาณข้อมูลไม่เพียงแต่ช่วยให้ AI ฉลาดขึ้น แต่ยังเป็นก้าวสำคัญในการวิจัยและพัฒนาโมเดลที่สามารถคิดวิเคราะห์และให้เหตุผลได้ดียิ่งขึ้น ทีมงานยังมีแผนพัฒนา เทคนิค Reinforcement Learning ที่สามารถขยายขนาดได้ เพื่อช่วยให้โมเดลมีศักยภาพสูงขึ้น และเข้าใกล้ขีดความสามารถระดับมนุษย์มากขึ้น
ที่มา – Github Alibaba
Leave a Reply