
Nvidia เปิดตัว Rubin ปฏิวัติสถาปัตยกรรมชิป AI: ก้าวสำคัญสู่ยุค Agentic AI และโครงสร้างพื้นฐานระดับล้านล้าน
Jensen Huang ประธานเจ้าหน้าที่บริหารของ Nvidia ประกาศเปิดตัวสถาปัตยกรรมคอมพิวเตอร์รุ่นใหม่ล่าสุดภายใต้ชื่อ “Rubin” ในงาน CES 2026 โดยระบุว่าเทคโนโลยีนี้เข้าสู่กระบวนการผลิต (Full Production) แล้ว เพื่อรองรับความต้องการที่เพิ่มขึ้นอย่างรวดเร็วของโมเดล AI ขนาดใหญ่และการคำนวณแบบ Agentic Reasoning
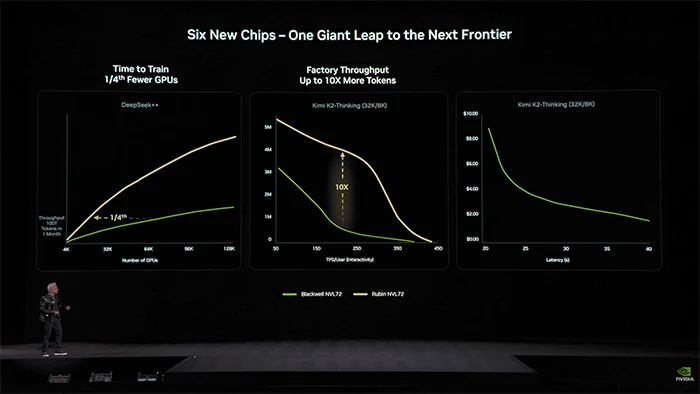
Technical Specifications สถาปัตยกรรม Rubin ถูกออกแบบมาเพื่อแก้ปัญหาคอขวดด้านหน่วยความจำและการรับส่งข้อมูล โดยมีตัวเลขเปรียบเทียบกับสถาปัตยกรรม Blackwell รุ่นก่อนหน้าดังนี้
- Floating Point Performance: Rubin ให้ประสิทธิภาพในงาน Inference สูงกว่าเดิม 5 เท่า และงาน Training สูงกว่าเดิม 3.5 เท่า โดยทำความเร็วสูงสุดได้ที่ 50 Petaflops บนรูปแบบข้อมูล NVFP4
- Transistor Count: ตัวชิป Rubin GPU มีทรานซิสเตอร์รวม 336 พันล้านตัว (เพิ่มขึ้น 1.6 เท่าจาก Blackwell)
- Energy Efficiency: ประสิทธิภาพการประมวลผลต่อวัตต์ (Inference compute per watt) เพิ่มขึ้นถึง 8 เท่า
- Memory Bandwidth: ใช้หน่วยความจำ HBM4 ขนาด 288GB ต่อ GPU ให้ Bandwidth รวมสูงถึง 22 TB/s (เพิ่มขึ้น 2.8 เท่าจาก HBM3e ในรุ่นก่อน)
องค์ประกอบของระบบนิเวศชิป (The Six-Chip Architecture) แพลตฟอร์ม Rubin ประกอบด้วยชิปหลัก 6 ตัวที่ทำงานประสานกันในระดับระบบ เพื่อรองรับเวิร์กโหลด AI ที่ซับซ้อน
- Rubin GPU: ชิปประมวลผลหลักสำหรับงาน AI Output Generation
- Vera CPU: ชิปประมวลผลกลางรุ่นใหม่ ใช้คอร์ Olympus (Arm-based) จำนวน 88 คอร์ ออกแบบมาเพื่อควบคุมตรรกะและการคิดวิเคราะห์ (Reasoning)
- Rubin CPX: หน่วยประมวลผลเสริมที่ใช้หน่วยความจำ GDDR7 (128GB) เพื่อรองรับงาน Context Retrieval และ Context Window ขนาดใหญ่ (สูงสุด 1 ล้าน Token+)
- NVLink 6 Switch: ระบบเชื่อมต่อรุ่นที่ 6 ให้ Bandwidth ระหว่าง GPU สูงถึง 3.6 TB/s
- ConnectX-9 SuperNIC: ระบบเน็ตเวิร์กที่รองรับความเร็วสูงสุด 1.6 Tb/s ต่อ GPU
- BlueField-4 DPU: ชิปประมวลผลด้านข้อมูลที่ทำหน้าที่จัดการ Cybersecurity, Storage และ Offload งานจาก CPU หลัก
Nvidia ได้เปิดตัว Inference Context Memory Storage Platform ซึ่งเป็นเลเยอร์การจัดเก็บข้อมูลใหม่ที่เชื่อมต่อภายนอก (External Storage Tier) ออกแบบมาเพื่อจัดการกับ KV Cache โดยเฉพาะ ช่วยให้โมเดลภาษาขนาดใหญ่ (LLM) สามารถประมวลผลงานระยะยาว (Long-term tasks) ได้อย่างมีประสิทธิภาพมากขึ้น โดยไม่ทำให้หน่วยความจำหลักของ GPU เต็ม
แพลตฟอร์มการใช้งาน (Deployment Platforms)
- Vera Rubin NVL72: ระบบตู้ Rack ที่ประกอบด้วย 72 Rubin GPUs และ 36 Vera CPUs เชื่อมต่อกันเป็นคอมพิวเตอร์เครื่องเดียว ให้ Bandwidth รวมในตู้สูงถึง 260 TB/s
- Vera Rubin NVL144 CPX: ออกแบบมาเพื่อรองรับงาน Inference ที่มี Context มหาศาล โดยการรวมชิป Rubin และ Rubin CPX เข้าด้วยกัน
Nvidia ยืนยันว่าพันธมิตรรายใหญ่ ได้แก่ OpenAI, Anthropic, และ AWS ได้เริ่มต้นกระบวนการจัดหาเพื่อนำ Rubin ไปใช้ในศูนย์ข้อมูลแล้ว ขณะที่โครงการซูเปอร์คอมพิวเตอร์ Doudna ของ Lawrence Berkeley National Lab จะเป็นหนึ่งในกลุ่มแรกที่ใช้งานสถาปัตยกรรมนี้ในการวิจัยทางวิทยาศาสตร์ โดย Jensen Huang ประเมินว่าตลาดโครงสร้างพื้นฐาน AI จะมีการใช้จ่ายรวมกว่า 3-4 ล้านล้านดอลลาร์ ในอีก 5 ปีข้างหน้า
ที่มา – TechCrunch
Leave a Reply